


Every day they told in the news how neural networks today will leave you personally without work. At the same time, few people understand how neural networks work inside? In this article, we will explain everything so that everyone understands.
How this article appeared: half of our team (developers) perfectly understands what neural networks are, what they have inside it, how it works. And the other half (marketing, design, projects and products, office managers) finally demanded an explanation with simply words, how does it work? So we apologize to all hardcore techies: we tried to be as simple as possible in order to give readers a general understanding of how neural networks work, and not to sort out all the deep technical nuances.
T9: language magic
Let's figure out what ChatGPT is from a technical point of view: it is not an intelligent being, not an analogue of a student or even a schoolboy in terms of intelligence. and you don't need to be afraid. In fact, ChatGPT is just T9 from the 2000s, but on crazy steroids! Both technologies are called «language models» (Language Models), and all they do is guess what the next word should be after the existing text.
Well, more precisely, in completely phones from the late 90s (like the cult indestructible Nokia), the original T9 technology only speeded up typing on push-button phones by guessing the current input, and not the next word. But the technology evolved, and by the era of smartphones in the early 2010s, it was already able to take into account the context (previous word), put punctuation and offer a choice of words that could go next. That's exactly the analogy with such an «advanced» version of T9/autocorrect is what we are talking about.
So both T9 and ChatGPT are trained to solve a really simple problem: predicting a single next word. This is language modeling - when, based on some existing text, a conclusion is made about what should be written next. In order to be able to make such predictions, the language models internally have to calculate the probabilities of the occurrence of certain words each time to continue. Otherwise, autocomplete on your phone would just give you completely random words with the same probability.
Example: You receive a message from a friend: "Let's go to a cafe today?". You start typing in response: “I can’t, I have plans, I’m going to ...”, and this is where T9 comes in. If he asks you to finish the sentence with a completely random word, like “I'm going to the mug” - then for such nonsense, to be honest, no language model is needed. Real autofill models in smartphones suggest much more relevant words.
So, how exactly does T9 understand which words are more likely to follow the already typed text, and which ones are definitely not worth suggesting?
Where do neural networks get word probabilities from?
Let's start with an even simpler question: how do you even predict the dependencies of some things on others? Suppose we want to teach a computer to predict the weight of a person depending on his height - how to do this?
First, we need to collect data on which we will look for the dependencies we are interested in (we will take statistics on height / weight for several thousand people), and then we will try to “train” the mathematical model to find patterns.
First, we need to collect data on which we will look for the dependencies we are interested in (we will take statistics on height / weight for several thousand people), and then we will try to “train” the mathematical model to find patterns.
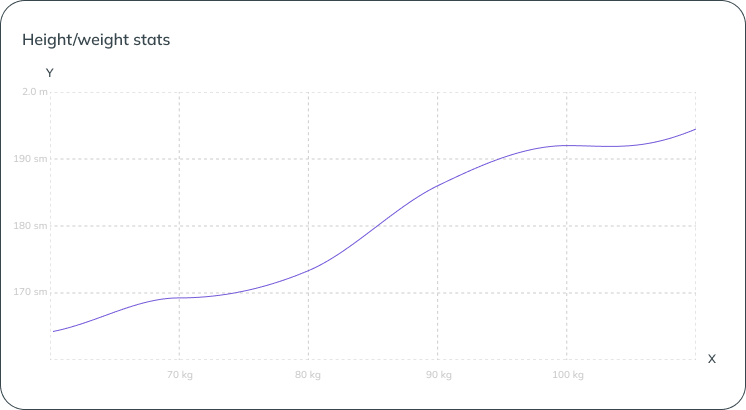
The graph shows a certain relationship: tall people, as a rule, weigh more. And this dependence is quite simple to express as a linear equation Y = k*X + b. In the picture, the line we need has already been drawn, it is it that allows us to select the coefficients of the equation k and b in such a way that the resulting line optimally describes the key dependence in our data set.
Neural networks are a set of approximately the same equations, only much more complex and using matrices with a huge number of parameters.
It can be simplified to say that T9 or ChatGPT are just cleverly chosen equations that try to predict the next word (Y from the equation) depending on the set of previous words fed to the input of the model (X from the equation).
The only difference between T9 and ChatGPT is that the first is a basic configuration model, and the second is the so-called large model (it has a very large number of parameters). In the field of Artificial Intelligence, they are called LLMs (Large Language Models).
Neural networks are a set of approximately the same equations, only much more complex and using matrices with a huge number of parameters.
It can be simplified to say that T9 or ChatGPT are just cleverly chosen equations that try to predict the next word (Y from the equation) depending on the set of previous words fed to the input of the model (X from the equation).
The only difference between T9 and ChatGPT is that the first is a basic configuration model, and the second is the so-called large model (it has a very large number of parameters). In the field of Artificial Intelligence, they are called LLMs (Large Language Models).
If you are already wondering why we are still talking about "predicting one next word", while the same ChatGPT answers with whole longreead - do not rack your brains. Language models easily generate long texts, but they do it on a word by word basis. Again, greatly simplifying, after generating each new word, the model re-runs through itself all the previous text along with the addition just written, and puts the next word, and the result is a coherent text.
Language models and creativity
In fact, language models try to predict not just a specific next word, but also the probabilities of different words that can be used to continue a given text. Why is this necessary, why can't you always look for the only, "most correct" word to continue? Let's take a look at an example.
Try to continue the text "The 44th President of the United States and the first African American in this position is Barak ...". Substitute the word that should be in place of the ellipsis and evaluate the likelihood that it will actually be there.
If you just said that the next word should be "Obama" with a 100% probability, then you are wrong! And it's not that there is some other 44th President of the United States Barak, it's just that in official documents his name is written in full, indicating his middle name Hussein. So a properly trained language model should ideally predict that in that sentence “Obama” will be the next word only with a conditional probability of 90%, and allocate the remaining 10% in case the text is continued by “Hussein” (after which Obama will follow with a probability of close to 100%).
And here we come to a very interesting aspect of language models: it turns out that they are not alien to a creative streak! In fact, when generating each next word, the model itself chooses it in a “random” way, as if throwing a die, but in such a way that the probabilities of “falling out” of different words approximately correspond to the probabilities that prompt the equations hardwired inside the model (derived when training the model on a huge array of different texts).
It turns out that the same model, even for absolutely identical requests, can give completely different answers - just like a living person. In general, scientists once tried to make neurons always choose the “most likely” next word as a continuation - which at first glance sounds logical, but in practice, for some reason, such models work worse; but a healthy element of randomness is strictly beneficial for them (increases the variability and, as a result, the quality of answers).
In general, our language is a structure with clear sets of rules and exceptions. Words in sentences do not appear out of nowhere, they are related to each other. These connections a person learns during growing up and schooling, through conversations, reading, and so on. At the same time, to describe the same event or fact, people come up with many ways in different styles, tones and semitones: fortunately, the approach to language communication between gopniks in the alley and philharmonic students is, fortunately, completely different.
A good model should contain all this variability of the language. The more accurately the model estimates the probabilities of words depending on the nuances of the context (the previous part of the text describing the situation), the better it is able to generate the answers that we want to hear from it.
Try to continue the text "The 44th President of the United States and the first African American in this position is Barak ...". Substitute the word that should be in place of the ellipsis and evaluate the likelihood that it will actually be there.
If you just said that the next word should be "Obama" with a 100% probability, then you are wrong! And it's not that there is some other 44th President of the United States Barak, it's just that in official documents his name is written in full, indicating his middle name Hussein. So a properly trained language model should ideally predict that in that sentence “Obama” will be the next word only with a conditional probability of 90%, and allocate the remaining 10% in case the text is continued by “Hussein” (after which Obama will follow with a probability of close to 100%).
And here we come to a very interesting aspect of language models: it turns out that they are not alien to a creative streak! In fact, when generating each next word, the model itself chooses it in a “random” way, as if throwing a die, but in such a way that the probabilities of “falling out” of different words approximately correspond to the probabilities that prompt the equations hardwired inside the model (derived when training the model on a huge array of different texts).
It turns out that the same model, even for absolutely identical requests, can give completely different answers - just like a living person. In general, scientists once tried to make neurons always choose the “most likely” next word as a continuation - which at first glance sounds logical, but in practice, for some reason, such models work worse; but a healthy element of randomness is strictly beneficial for them (increases the variability and, as a result, the quality of answers).
In general, our language is a structure with clear sets of rules and exceptions. Words in sentences do not appear out of nowhere, they are related to each other. These connections a person learns during growing up and schooling, through conversations, reading, and so on. At the same time, to describe the same event or fact, people come up with many ways in different styles, tones and semitones: fortunately, the approach to language communication between gopniks in the alley and philharmonic students is, fortunately, completely different.
A good model should contain all this variability of the language. The more accurately the model estimates the probabilities of words depending on the nuances of the context (the previous part of the text describing the situation), the better it is able to generate the answers that we want to hear from it.
2018: GPT-1 transforms language models
Let's move on from the ancient T9 to modern models: ChatGPT, which made a splash, is the most recent representative of the GPT family of models. But in order to understand how he managed to acquire such unusual abilities of natural responses for a person, we need to return to the origins again.
GPT stands for Generative Pre-trained Transformer, or "transformer trained to generate text." Transformer is the name of a neural network architecture invented by Google researchers in 2017.
It was the invention of the Transformer that turned out to be so significant that all areas of artificial intelligence - from text translations to image, sound or video processing - began to actively adapt and apply it. The artificial intelligence industry then moved from the so-called "winter" to rapid development, and was able to overcome the stagnation.
Conceptually, the Transformer is a universal computational mechanism that is very easy to describe: it takes one set of sequences (data) as input and outputs the same set of sequences, but a different one, transformed according to some algorithm. Since text, pictures and sound (and indeed almost everything in this world) can be represented as sequences of numbers, with the help of the Transformer you can solve almost any problem.
But the main feature of the Transformer is its convenience and flexibility: it consists of modules-blocks that are very easy to scale. If the old, pre-transformer language models required too many resources when they were tried to be forced to “swallow” quickly and many words at a time, then transformer neural networks cope with this task much better.
Earlier approaches had to process input data one by one, that is, sequentially. Therefore, when the model worked with a one-page text, by the middle of the third paragraph, she forgot what happened at the very beginning (everything is like with people). But the Transformer is able to look at everything, everywhere and at once - and this leads to much more impressive results.
This is what made it possible to make a breakthrough: now the model reuses what has already been written earlier, constantly keeps the context, and most importantly, it can build connections like “every word with every” on very impressive amounts of data.
GPT stands for Generative Pre-trained Transformer, or "transformer trained to generate text." Transformer is the name of a neural network architecture invented by Google researchers in 2017.
It was the invention of the Transformer that turned out to be so significant that all areas of artificial intelligence - from text translations to image, sound or video processing - began to actively adapt and apply it. The artificial intelligence industry then moved from the so-called "winter" to rapid development, and was able to overcome the stagnation.
Conceptually, the Transformer is a universal computational mechanism that is very easy to describe: it takes one set of sequences (data) as input and outputs the same set of sequences, but a different one, transformed according to some algorithm. Since text, pictures and sound (and indeed almost everything in this world) can be represented as sequences of numbers, with the help of the Transformer you can solve almost any problem.
But the main feature of the Transformer is its convenience and flexibility: it consists of modules-blocks that are very easy to scale. If the old, pre-transformer language models required too many resources when they were tried to be forced to “swallow” quickly and many words at a time, then transformer neural networks cope with this task much better.
Earlier approaches had to process input data one by one, that is, sequentially. Therefore, when the model worked with a one-page text, by the middle of the third paragraph, she forgot what happened at the very beginning (everything is like with people). But the Transformer is able to look at everything, everywhere and at once - and this leads to much more impressive results.
This is what made it possible to make a breakthrough: now the model reuses what has already been written earlier, constantly keeps the context, and most importantly, it can build connections like “every word with every” on very impressive amounts of data.
2019: GPT-2 or how to cram everything Tolstoy into the language model?
If you want to teach a neural network to recognize images and distinguish a cat from an owl, then you can’t just tell it “here is a link to a giant archive of 100,500 photos of cats and owls – sort it out!”. No, in order to train the model, you must first label the training dataset - that is, show it on each photo and label it.

Do you know what is great about learning language models? The fact that after the training array they can be given any textual data that does not need to be marked up in a special way. It's as if a schoolboy could throw a portfolio with a variety of books without explanation, and he himself would come up with some conclusions in the process of reading!
The Transformers technology tested on GPT-1 turned out to be extremely successful in terms of scaling: it can work with large amounts of data and “massive” models (consisting of a huge number of parameters) much more efficiently than its predecessors. Well, scientists from OpenAI in 2019 made the same conclusion: “We will make hefty language models!”
The Transformers technology tested on GPT-1 turned out to be extremely successful in terms of scaling: it can work with large amounts of data and “massive” models (consisting of a huge number of parameters) much more efficiently than its predecessors. Well, scientists from OpenAI in 2019 made the same conclusion: “We will make hefty language models!”
In general, it was decided to radically upgrade GPT-2 in two key areas: the training data set (dataset) and the model size (number of parameters).
At that time, there were no special, large, high-quality, public text data sets for training language models - so each team of AI specialists had to pervert according to their own degree of corruption. And the guys at OpenAI went to the most popular English-language online forum, Reddit, and siphoned off all hyperlinks from all posts that had more than three likes (scientific approach!). In total, there were about 8 million links, and the texts downloaded from them weighed about 40 gigabytes.
At that time, there were no special, large, high-quality, public text data sets for training language models - so each team of AI specialists had to pervert according to their own degree of corruption. And the guys at OpenAI went to the most popular English-language online forum, Reddit, and siphoned off all hyperlinks from all posts that had more than three likes (scientific approach!). In total, there were about 8 million links, and the texts downloaded from them weighed about 40 gigabytes.
Is it a lot or a little? If you add up all the works of Tolstoy, you get 7,670,000 words.
This will include 3M word fiction, 2.2M word non-fiction, 1.7M word letters, 600K word diaries, 170K word notebooks
And it will still be less than the size of the GPT-2 training sample. Given that people read on average one page per minute, even if you absorb text 24 hours a day without a break for food and sleep, one human life will not be enough to catch up with GPT-2.
But the amount of training data alone is not enough to get a cool language model: the model itself must also be complex and voluminous enough to fully “swallow” and “digest” such an amount of information. And how to measure this complexity of the model, what is it expressed in?
Remember, we said a little earlier that inside language models (in a super-simplified approximation) live equations of the form Y = k*X + b, where the desired Y is the next word whose probability we are trying to predict, and X are the words in the input , on the basis of which we make a prediction?
And it will still be less than the size of the GPT-2 training sample. Given that people read on average one page per minute, even if you absorb text 24 hours a day without a break for food and sleep, one human life will not be enough to catch up with GPT-2.
But the amount of training data alone is not enough to get a cool language model: the model itself must also be complex and voluminous enough to fully “swallow” and “digest” such an amount of information. And how to measure this complexity of the model, what is it expressed in?
Remember, we said a little earlier that inside language models (in a super-simplified approximation) live equations of the form Y = k*X + b, where the desired Y is the next word whose probability we are trying to predict, and X are the words in the input , on the basis of which we make a prediction?
So, what do you think: how many parameters were there in the equation describing the largest GPT-2 model in 2019? Maybe a hundred thousand, or a couple of million? There were one and a half billion parameters. These parameters (also called "weights" or "coefficients") are obtained during the training of the model, then saved, and no longer change. That is, when using the model, a different X is substituted into this giant equation each time (words in the input text), but the equation parameters themselves (numerical coefficients k at X) remain unchanged.
The more complex the equation is wired into the model (the more parameters it contains), the better the model predicts the probabilities, and the more believable the text it generates will be. And for this largest GPT-2 model at that time, the texts suddenly began to turn out so good that the researchers from OpenAI were even afraid to publish the model in the open for security reasons. Well, how would people rush to generate realistic-looking fakes, spam for social networks and so on?
It really was a significant breakthrough in quality! You remember: previous T9 / GPT-1 models, at the very least, could only suggest one next word. But GPT-2 has already easily written an essay on behalf of a teenager answering the question: “What fundamental economic and political changes are needed to effectively respond to climate change?”. The text of the answer was sent under a pseudonym to the jury of the corresponding competition - and they did not notice any catch. The ratings for this work were not the highest and it did not make it to the final - but also “what nonsense you sent us, you would be ashamed !!” no one exclaimed either.
The transition from quantity to quality
In general, the idea that as the size of the model grows, it unpredictably opens up qualitatively new properties (for example, to write coherent essays with meaning instead of simply prompting the next word on the phone) is a rather surprising feature. Let's take a closer look at the newly acquired GPT-2 skills.
There are special sets of tasks for resolving ambiguity in the text, which help to assess the understanding of the text (at least by a person, even by a neural network). For example, compare two statements:
There are special sets of tasks for resolving ambiguity in the text, which help to assess the understanding of the text (at least by a person, even by a neural network). For example, compare two statements:
- The fish took the bait. She was delicious.
- The fish took the bait. She was hungry.
What object does the pronoun "she" in the first example refer to - a fish or a bait? And in the second case? Most people easily understand from the context that in one case "she" is a bait, and in another case a fish. But in order to realize this, you need not just read the sentence - but build a whole picture of the world in your head! After all, for example, fish can be both hungry and tasty in different situations (on a plate in a restaurant). The conclusion about her "hunger" in this particular example follows from the context and her actions.
Humans get these problems right about 95% of the time, but early language models only got it right about half the time.
Humans get these problems right about 95% of the time, but early language models only got it right about half the time.
You probably thought: “Well, you just need to accumulate a large database of such problems (for a couple of thousand examples) with answers, drive through the neural network - and train it to find the right answer.” And with old models (with a smaller number of parameters) they tried to do just that - but they managed to reach only 60% of success. But no one taught GPT-2 such tricks on purpose; but she took it, and she herself unexpectedly and confidently surpassed her predecessors and herself learned to identify hungry fish correctly in 70% of cases.
This is the same transition from quantity to quality, and it occurs completely non-linearly: for example, with an increase in the number of parameters by a factor of three from 115 to 350 million, there are no significant changes in the accuracy of solving “fish” problems by the model, but with an increase in the size of the model two times more to 700 million parameters - a qualitative leap occurs, the neural network suddenly "sees the light" and begins to amaze everyone with its success in solving tasks completely unfamiliar to it, which it had never met before and did not specifically study them.
GPT-2 was released in 2019 and surpassed GPT-1 both in terms of the amount of training text data and the size of the model itself by 10 times. Such a quantitative growth led to the fact that the model suddenly self-learned qualitatively new skills: from writing long essays to solving tricky problems that require building a picture of the world.
2020: evolution to GPT-3
Getting used to the smarter GPT-2, OpenAI thought: Why not increase the model again by 100? And GPT-3, released in 2020, already boasted 116 times more parameters - 175 billion! At the same time, the raskabanevshey grid itself began to weigh an incredible 700 gigabytes.
The GPT-3 training data set was also pumped over: it increased by about 10 times to 420 gigabytes - a huge pile of books, Wikipedia, and many more texts from various sites were stuffed there. It is definitely unrealistic for a living person to absorb such a volume of information.
The GPT-3 training data set was also pumped over: it increased by about 10 times to 420 gigabytes - a huge pile of books, Wikipedia, and many more texts from various sites were stuffed there. It is definitely unrealistic for a living person to absorb such a volume of information.
An interesting nuance immediately catches your eye: unlike GPT-2, the model itself is now larger (700 GB) than the entire array of text for its training (420 GB). It turns out a paradox: now the neural network in the process of studying raw data generates information about various interdependencies within them, which exceeds the original information in volume.
Such a generalization (comprehension?) by the model makes it possible to extrapolate even better than before - to show good results in tasks for generating texts that were very rare or not encountered at all during training. Now it’s definitely not necessary to teach the model to solve a specific problem - instead, it’s enough to describe the problem in words, give a few examples, and GPT-3 will grab on the fly what they want from it!
And then once again it turned out that GPT-3 bypasses many specialized models that existed before it: for example, translating texts from French or German into English immediately began to be given to GPT-3 easier and better than any other neural networks specially designed for this, even though no one taught her. How?! Let me remind you that we are talking about a linguistic model, whose purpose, in fact, was exactly one thing - to try to guess one next word to a given text. Where does the ability to translate come from?
But even more amazing is that GPT-3 was able to teach itself math! The graph below shows the accuracy of the responses of neural networks with a different number of parameters to tasks related to addition / subtraction, as well as multiplication of numbers up to five digits. As you can see, when moving from models with 10 billion parameters to 100 billion, neural networks suddenly and abruptly begin to “be able” in mathematics.
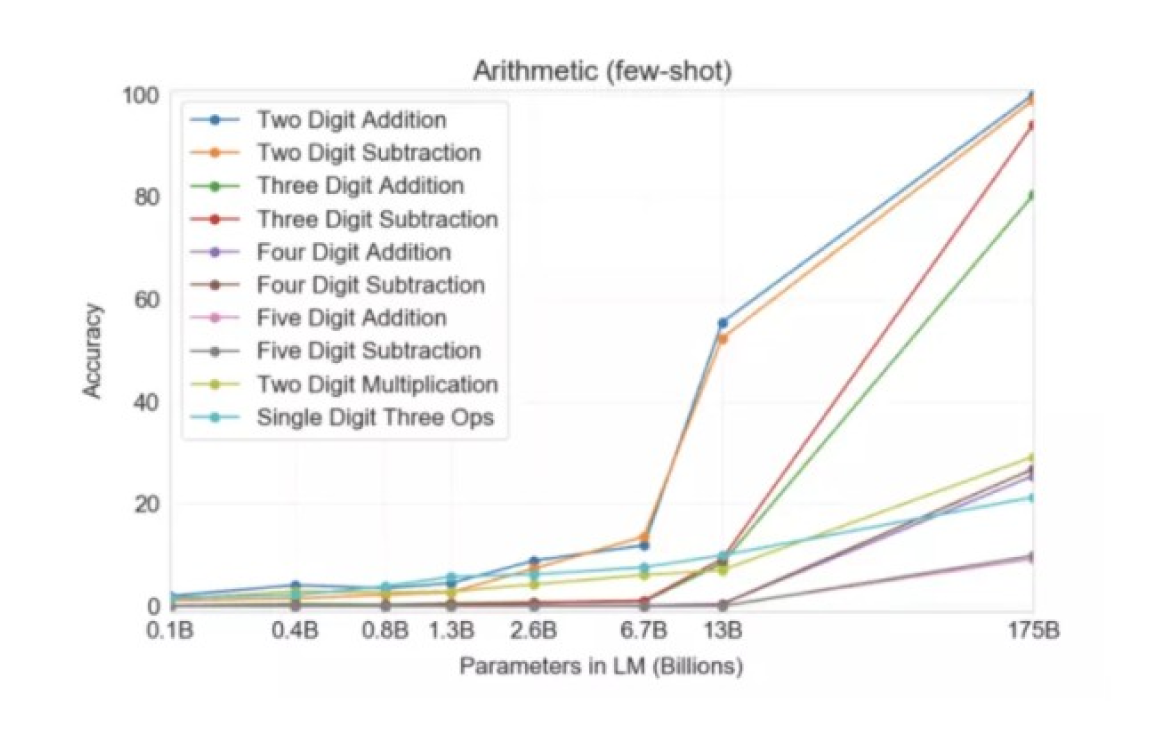
Horizontally - the number of parameters in the model (in billions), vertically - the quality of the model, expressed as a percentage of correctly solved mathematical examples
The language model was taught to continue the texts with words, and at the same time she was somehow able to figure out for herself that if she was typed “472 + 105 =”, then it was “577” that should be answered. Although, some say “the neural network just managed to see all the options and stupidly remember them in the training data” - so the debate about whether this is magic or “just like that” is still ongoing.
In the graph above, the most interesting thing is that when the model size increases (from left to right), at first nothing seems to change, and then suddenly a qualitative leap occurs, and GPT-3 begins to “understand” how to solve this or that problem. How, what, why it works - no one knows for sure. But it works somehow; moreover, not only in mathematics - but in general in a wide variety of other tasks!
By the way, GPT-3 already solves the problem about fish with an accuracy of over 90% - just like a person. It makes you think, really: what new skills will the neural network acquire if its volume is increased by a hundred again?
By the way, GPT-3 already solves the problem about fish with an accuracy of over 90% - just like a person. It makes you think, really: what new skills will the neural network acquire if its volume is increased by a hundred again?
The right promts
Let's first understand what it means - "the model can solve problems"? The process looks like this: we feed a certain text with a request to the input of the model, and it adds a continuation to it. If this continuation coincides with our expectations, then the model has solved its task.
The text that we submit to the input is called prompt (“request”).
The more precisely the prompt describes what we want, the better the model will understand what it needs to do, you can still send it examples for a better result.
The text that we submit to the input is called prompt (“request”).
The more precisely the prompt describes what we want, the better the model will understand what it needs to do, you can still send it examples for a better result.
Without a description of the goal and without examples in the prompt, the model also usually understands the problem, but offers solutions that are not as good in quality. We can say that a detailed prompt allows GPT to better estimate the probabilities of the words to be generated as an answer.
How complex should a prompt be? How close is the model to our understanding? More recently, researchers have found that to significantly improve the results of generation, you need to add just one phrase to the prompt - “let's think step by step” (let's think step by step). It turned out that this encourages the model to reason consistently, draw conclusions based on its own judgments, and come to the correct answer much more often than without this phrase.
How it works? Let's use the example of a children's problem:
Promt: On average, boxer Ivan delivers 25 punches per minute. The fight lasts 5 rounds of 3 minutes. How many punches did he throw?
Chat-GPT replied: 255 hits.
However, the same model can answer like this:
Promt: On average, boxer Ivan delivers 25 punches per minute. The fight lasts 5 rounds of 3 minutes. How many punches did he throw? Let's think step by step.
Answer: Ivan delivers 25 blows in one minute. In three minutes, Ivan delivers 3 * 25 = 75 hits. For five rounds, Ivan delivers 5 * 75 = 375 hits.
Promt: On average, boxer Ivan delivers 25 punches per minute. The fight lasts 5 rounds of 3 minutes. How many punches did he throw?
Chat-GPT replied: 255 hits.
However, the same model can answer like this:
Promt: On average, boxer Ivan delivers 25 punches per minute. The fight lasts 5 rounds of 3 minutes. How many punches did he throw? Let's think step by step.
Answer: Ivan delivers 25 blows in one minute. In three minutes, Ivan delivers 3 * 25 = 75 hits. For five rounds, Ivan delivers 5 * 75 = 375 hits.
It can be seen that this answer has become longer, the solution of the problem turned out like a schoolboy, in three steps. And the final number 375 is the correct answer.
This “reasoning mode” is one of the qualitatively new features that appeared in the “large” GPT-3 model after overcoming the bar of a hundred billion parameters. Previous models did not know how to conjure like that.
As you already understood, compiling competent prompts for a model is a separate science. Under this task, the positions of “prompt engineer” appear (that is, a person who writes queries for language models).
This “reasoning mode” is one of the qualitatively new features that appeared in the “large” GPT-3 model after overcoming the bar of a hundred billion parameters. Previous models did not know how to conjure like that.
As you already understood, compiling competent prompts for a model is a separate science. Under this task, the positions of “prompt engineer” appear (that is, a person who writes queries for language models).
2022: InstructGPT and its human upbringing
In fact, increasing the size of language models does not in itself mean that they will respond to queries exactly the way their user wants them to. Indeed, when we formulate some kind of request, we often mean a lot of hidden conditions - which in communication between people are taken for granted, or something. For example, when you ask your child to wash the dishes, you don't say wash the dishes with a sponge in the sink with detergent, because it goes without saying.
But language models, to be honest, are not very similar to people - therefore, they often have to prompt and chew on those things that seem obvious to people. But it would be great if the models, firstly, understood / generated more detailed and relevant instructions from the request for themselves, and secondly, predicted how a person would act in a similar situation.
The lack of such abilities is due to the fact that GPT-3 is trained to simply predict the next word in a giant set of texts.
The lack of such abilities is due to the fact that GPT-3 is trained to simply predict the next word in a giant set of texts.
To solve this problem, you need the model to pull accurate and useful answers on demand; but at the same time, these answers must also be harmless and non-toxic. When researchers thought about this problem, it quickly became clear that the properties of the model "accuracy / usefulness" and "harmlessness / non-toxicity" quite often contradict each other. After all, an exact model should honestly issue instructions for the request “ok, Google, how to make a Molotov cocktail”, and a model sharpened for maximum harmlessness will respond to such a prompt “sorry, I’m afraid that my answer may offend someone on the Internet.” So it turns out that the creation of AI, equated to a person in terms of values, is a difficult task of finding a balance, in which there is no unambiguous correct answer.
There are a lot of complex ethical issues around this “AI alignment” (OpenAI) problem lately, and we will not analyze them all now (perhaps in the next article). The main snag here is that there are a huge number of such controversial situations, and it is simply not possible to formalize them somehow clearly. People themselves cannot agree among themselves what is good and what is bad, and then they can formulate rules that are understandable for the robot ...
As a result, the researchers did not come up with anything better than just giving the model a lot of feedback, however, human children learn morality in this way: they do a lot of different things from childhood and carefully monitor the reactions of adults.
InstructGPT (also known as GPT-3.5) is exactly the GPT-3, which was further trained using feedback on the assessments of a living person. Literally, a bunch of people sat and evaluated a bunch of answers from the neural network: how well they correspond to their expectations, taking into account the request issued to it. And the language model learned to solve another problem - “how can I change my answer in such a way that it gets the highest rating from a person?”.
Moreover, from the point of view of the general process of training the model, this final stage of “additional training on living people” takes no more than 1%. But it's that final touch that's what made the latest GPT series models so amazing! It turns out that GPT-3 already had all the necessary knowledge before that: it understood different languages, remembered historical events, knew the differences in the styles of different authors, and so on. But only with the help of feedback from other people, the model learned to use this knowledge in exactly the way that people consider “correct”.
November 2022: ChatGPT as we know it
ChatGPT was released in November 2022 - about 10 months after its predecessor InstructGPT and instantly thundered all over the world. It seems that for the past few months even the grandmothers on the benches have been discussing what this ChatZhPT of yours said there, and who, according to the latest forecasts, is about to leave without a job.
At the same time, from a technical point of view, ChatGPT does not have powerful differences from InstructGPT, the new model has been trained to work as an "AI assistant" in a dialogue format: for example, if the user's request is unclear, then you can and should ask a clarifying question, and so on.
This begs the question - why didn't we admire GPT-3.5 at the beginning of 2022? Despite the fact that Sam Altman (executive director of OpenAI) honestly admitted that the researchers themselves were surprised at such a rapid success of ChatGPT - after all, a model comparable to it in terms of abilities had been quietly lying on their website for more than ten months by that time, and no one was up to this case.
It seems that the main secret of the success of the new ChatGPT is just a user-friendly interface! InstructGPT could only be accessed through a special API - that is, it was not so easy for an ordinary person to go there. And ChatGPT was seated in the familiar “dialog window” interface, just like in messengers familiar to everyone. Moreover, they opened public access in general for everyone in a row - and people massively rushed to conduct dialogues with the neural network, screen them and share them on social networks.
As in any technology startup, not only the technology itself was important here, but also the wrapper in which it was wrapped. You can have the best model or the smartest chatbot - but nobody will be interested in them if they do not come with a simple and understandable interface. And ChatGPT made a breakthrough in this sense, bringing the technology to the masses through the usual dialog box in which a friendly robot "prints" the answer right before our eyes, word by word.
Not surprisingly, ChatGPT set absolute records for the speed of attracting new users: it reached the mark of 1 million users in the first five days after the release, and exceeded 100 million in just two months.
The ChatGPT model was released in November 2022 and from a technical point of view there were no special innovations. But on the other hand, she had a convenient interaction interface and open public access.
So, what we got?
The article turned out. let's just say. long, we hope that you were interested, and you began to understand a little better what is happening under the hood of neural networks.
The ChatGPT model was released in November 2022 and from a technical point of view there were no special innovations. But on the other hand, she had a convenient interaction interface and open public access.
So, what we got?
The article turned out. let's just say. long, we hope that you were interested, and you began to understand a little better what is happening under the hood of neural networks.


